Web scraping with morph.io
If you’ve followed along my previous two blog posts, Web Scraping with Ruby and Advanced web scraping with Mechanize then you’ll now have the knowledge needed to write a basic web scraper for getting structured data from the web.
The next logical step is to actually run these scrapers regularly so you can get information that’s constantly up-to-date. This is where the excellent morph.io from the talented folks at OpenAustralia comes into play.
Morph.io bills itself as “A Heroku for Scrapers”. You can choose to either run your scrapers manually, or have them run automatically for you every day. Then you can use the morph.io API to extract the data for use in your application as JSON, CSV or you can download a sqlite database containing the scraped data.
Morph.io fills the gap that Scraperwiki Classic left. Morph.io scrapers are hosted on GitHub, which means you can fork them and fix them if they break in the future.
Creating a scraper
We’ll use the code from the Pitchfork Scraper in my previous post to demonstrate how easy it is to get your scraper running on morph.io.
You can sign into morph.io with a GitHub account. Once signed in you can then create a scraper. Currently morph.io supports scrapers written in Ruby, PHP, Python or Perl, choose a language and give your scraper a name, I’m calling mine pitchfork_scraper. Then press the “Create Scraper” button to create a new GitHub repository containing skeleton code for a scraper in your chosen language.
Clone the repository that was created in the previous step, in my case I can use the following:
git clone https://github.com/chrismytton/pitchfork_scraper
The repository will contain a README.md and a scraper.rb file.
Morph.io expects two things from your scraper. First the scraper repository should contain a scraper.rb file for Ruby scrapers 1, second the scraper itself should write to a sqlite3 database file called data.sqlite. In order to change this in our scraper we need to make a small change so it writes to a database rather than to JSON on STDOUT.
First add the code from the previous post into scraper.rb, then you can change the code to use the scraperwiki gem to write to the sqlite database.
diff --git a/scraper.rb b/scraper.rb
index 2d2baaa..f8b14d6 100644
--- a/scraper.rb
+++ b/scraper.rb
@@ -1,6 +1,8 @@
require 'mechanize'
require 'date'
-require 'json'
+require 'scraperwiki'
+
+ScraperWiki.config = { db: 'data.sqlite', default_table_name: 'data' }
agent = Mechanize.new
page = agent.get("http://pitchfork.com/reviews/albums/")
@@ -34,4 +36,6 @@ reviews = review_links.map do |link|
}
end
-puts JSON.pretty_generate(reviews)
+reviews.each do |review|
+ ScraperWiki.save_sqlite([:artist, :album], review)
+end
This uses the ScraperWiki.save_sqlite method to save the review in the database. The first argument is the list of fields that in combination should be considered unique. In this case we’re using the artist and album, since it’s unlikely that an artist would release two albums with the same name.
You’ll need to install the Ruby scraperwiki gem in addition to the other dependencies to run this code locally.
gem install scraperwiki
Then you can run this code on your local machine with the following:
ruby scraper.rb
This will create a new file in the current directory called data.sqlite which will contain the scraped data.
Running the scraper on morph.io
Now you’ve made the changes to your scraper you can run the code on morph.io. First commit your changes using git. Then git push the changes to the scrapers GitHub repository.
You can then run the scraper and the results should be added to the corresponding sqlite database on morph.io. It should look something like the following:
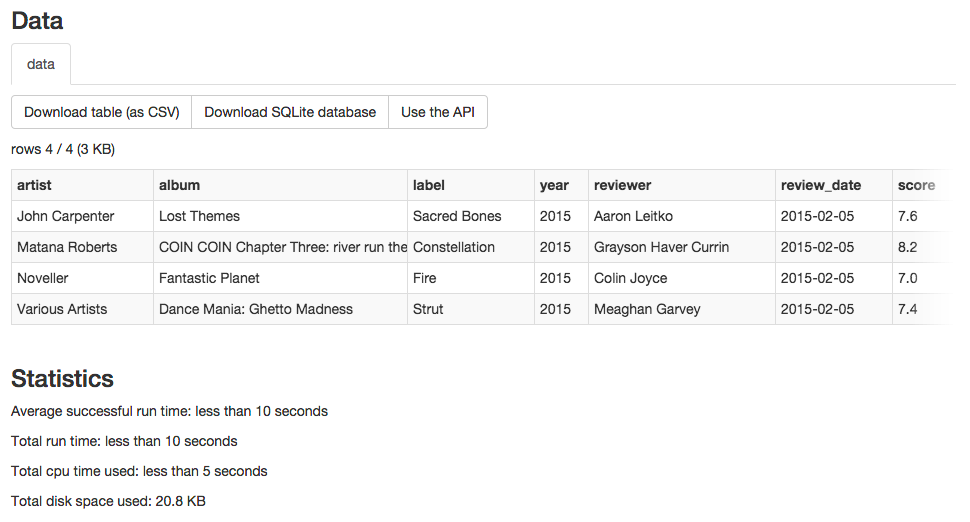
As you can see the data is now available to authorized users as either JSON, CSV or you can download the sqlite database and use that locally.
The code for the scraper is available on GitHub. You can see the output from the scraper on morph.io morph.io/chrismytton/pitchfork_scraper. Note that you’ll need to sign in with GitHub in order to access and manipulate the data over the API.
This article should give you enough background to start hosting your scrapers on morph.io. In my opinion it’s an awesome service that takes the hassle out of running and maintaining scrapers and leaves you to concentrate on the unique parts of your application.
Go forth and get structured data out of the web!
-
Alternatively
scraper.pyfor Python,scraper.phpfor PHP orscraper.plfor Perl ↩